import this # improt를 통해 파이썬의 라이브러리나 패키지를 가져올 수 있음3: 데이터 분석 준비하기
부스트코스
Zen of Python
- 파이썬의 철학이 잘 담겨있는 Zen of Python을 출력해 봅니다. (아래의 실습을 통해 확인해 보세요!)
boolean
파이썬에서는 명시적인 것이 암시적인 것보다 낫다라는 철학이 있습니다.
True나 False는 0과 1로도 표현할 수 있으나 명시적으로 표현하기 위해 True와 False를 사용합니다.
TrueTrueFalseFalseTrue == 1TrueFalse == 0TrueTrue == "1" # True와 문자 1과는 다르다! 1따옴포=문자열FalseTrue != "1"TrueFalse == "0"FalseFalse != "0"TrueTrue and TrueTrueTrue and FalseFalseTrue or False #or연산자: 하나만 true여도 trueTruenumber and String
- 숫자 1과 문자 “1”은 다르다! 데이터 타입 “type” 사용
"1"'1'type(1)inttype("1")strStrings and Lists
til = "Today I learned"
til'Today I learned'til.lower() #다 소문자로 변경'today i learned'til.upper() #대문자 변경'TODAY I LEARNED'# 비어있는 리스트 만들기. lang라는 변수에 담기
lang = []
lang[]lang.append("python")
lang.append("java")
lang.append("c")
lang['python', 'java', 'c']lang[0] #lnag이라는 변수에 담겨있는 언어명을 인덱싱을 통해 가져오기'python'lang[1]'java'lang[-1]'c'Control Flow
- 제어문-조건문, 반복문
for i in lang:
print(i)python
java
cfor i in lang:
if i == "python":
print("python")
else:
print("기타") # indent를 맞춰줘야 한다.python
기타
기타# 특정 횟수만큼 반복문 실행
count = len(lang)
for i in range(count):
print(lang[i]) python
java
c# 짝수일때 python을 홀수일때 java출력
for i in range(1,10): # `1에서 9까지
if i % 2 == 0: #짝수만 출력
print("python")
else:
print("java")java
python
java
python
java
python
java
python
java# enumerate를 사용하면 인덱스 번호와 원소를 같이 가져온다
for i, val in enumerate(lang):
print(i,val)0 python
1 java
2 c문자열
address = " 경기도 성남시 분당구 불정로 6 NAVER 그린팩토리 16층 "
address' 경기도 성남시 분당구 불정로 6 NAVER 그린팩토리 16층 '# 앞뒤 공백 제거
# 데이터 전처리 시 주로 사용
address = address.strip()
address'경기도 성남시 분당구 불정로 6 NAVER 그린팩토리 16층'# 문자열 길이
len(address)33# 공백으로 문자열 분리
address_list = address.split()
address_list['경기도', '성남시', '분당구', '불정로', '6', 'NAVER', '그린팩토리', '16층']슬라이싱, startswith, in 을 통해 문자열에 경기아 있는지 확인하기
address[:2]'경기'address.startswith("경기")True"경기" in address True리스트
- 문자열에서 쓰는 방법과 비슷한 메소드 등을 사용
address_list[2]'분당구'street = address_list[3]
street'불정로'address_list[-1]'16층'# "".join(리스트)를 사용하면 리스트를 공백 문자열로 연결 한다
"-".join(address_list)'경기도-성남시-분당구-불정로-6-NAVER-그린팩토리-16층'"경기" in address_listFalse"경기도" in address_listTrue"분당구" in address_listTrue# pandas (패널 데이터 앤 시스템의 약자)
# 수식과 그래프를 통해 계산 및 시각화하는 도구
# 엑셀을 사용 했을때보다 대용량 데이터를 쓸수 있고 소스 코드 파일만 데이터 프레임 로드를 해서 소스코드들을 재사용 할 수 있다.
# 월별 작업과 같은 반복작업..
# 아래에 첨부된 10 minutes to pandas를 한 번씩 실행해보시면 판다스의 전반적인 것을 익힐 수 있습니다.
# 추가로 같이 첨부된 Pandas Cheat Sheet도 추천드립니다.import pandas as pdpd.DataFrame?# 공식문서 (도움말) 활용하기
pd.DataFrame()
# shift+tab+tabDataFrame
df = pd.DataFrame(
{"a" : [4, 5, 6, 6],
"b" : [7, 8, 9, 9],
"c" : [10, 11, 12, 12]},
index = [1, 2, 3, 4])
df| a | b | c | |
|---|---|---|---|
| 1 | 4 | 7 | 10 |
| 2 | 5 | 8 | 11 |
| 3 | 6 | 9 | 12 |
| 4 | 6 | 9 | 12 |
Series
# 1차원 자료구조.. (벡터!)
df["a"]
# 출력된 형태: series 데이터1 4
2 5
3 6
Name: a, dtype: int64# dataframe으로 변경 (2차원 자료구조) (행렬!)
df[["a"]]| a | |
|---|---|
| 1 | 4 |
| 2 | 5 |
| 3 | 6 |
Subset
df[df["a"] > 4]| a | b | c | |
|---|---|---|---|
| 2 | 5 | 8 | 11 |
| 3 | 6 | 9 | 12 |
df["a"]1 4
2 5
3 6
Name: a, dtype: int64df[["a","b"]]
# df["a","b"] 이렇게 쓰면 오류가 난다. 대괄호를 또 해주기 | a | b | |
|---|---|---|
| 1 | 4 | 7 |
| 2 | 5 | 8 |
| 3 | 6 | 9 |
Summarize Data
df["a"].value_counts()
# 빈도수 계산6 2
4 1
5 1
Name: a, dtype: int64len(df)4Reahaping
- sort_values, drop
df.sort_values("a",ascending=False)
#ascending= 역수 | a | b | c | |
|---|---|---|---|
| 3 | 6 | 9 | 12 |
| 4 | 6 | 9 | 12 |
| 2 | 5 | 8 | 11 |
| 1 | 4 | 7 | 10 |
df = df.drop(["c"], axis=1)
# 기본 설정은 axis=0 으로 되어있으므로 axis를 바꿔줘야 함
df| a | b | |
|---|---|---|
| 1 | 4 | 7 |
| 2 | 5 | 8 |
| 3 | 6 | 9 |
| 4 | 6 | 9 |
Group Data
- Groupby, pivot_table
# "a" 컬럼값을 Groupby하여 "b"의 컬럼값 구하기
df.groupby(["a"])["b"].mean()a
4 7.0
5 8.0
6 9.0
Name: b, dtype: float64df.groupby(["a"])["b"].agg(["mean", "sum", "count"])| mean | sum | count | |
|---|---|---|---|
| a | |||
| 4 | 7.0 | 7 | 1 |
| 5 | 8.0 | 8 | 1 |
| 6 | 9.0 | 18 | 2 |
df.groupby(["a"])["b"].describe() #요약하는거| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| a | ||||||||
| 4 | 1.0 | 7.0 | NaN | 7.0 | 7.0 | 7.0 | 7.0 | 7.0 |
| 5 | 1.0 | 8.0 | NaN | 8.0 | 8.0 | 8.0 | 8.0 | 8.0 |
| 6 | 2.0 | 9.0 | 0.0 | 9.0 | 9.0 | 9.0 | 9.0 | 9.0 |
pd.pivot_table(df, index="a", values="b", aggfunc="sum")| b | |
|---|---|
| a | |
| 4 | 7 |
| 5 | 8 |
| 6 | 18 |
Plotting
df.plot.bar()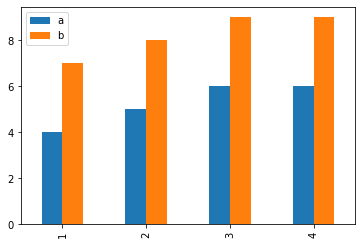
!conda env list# conda environments:
#
base /home/koinup4/anaconda3
py37 * /home/koinup4/anaconda3/envs/py37
py39 /home/koinup4/anaconda3/envs/py39